
&w=3840&q=75)
Kosten-Optimierung für OpenClaw Agenten
Nach mehreren Wochen praktischer Erfahrung mit OpenClaw zeigt sich, dass die Token-Kosten bei der Arbeit mit KI-Agenten schnell außer Kontrolle geraten können. Durch systematisches Tracking der Tokenverbräuche und die Entwicklung eines Dashboards gelang es, die täglichen Kosten von anfangs 50-80 Dollar auf einen einstelligen Bereich zu reduzieren.
Wer mit KI-Agenten wie OpenClaw und Large Language Models arbeitet, kennt das Problem: Die Kosten können schnell explodieren. Ich spreche hier nicht von ein paar Euro im Monat – wir reden von 50 bis 80 Dollar täglich, die sich in Token-Gebühren auflösen. Das ist der Punkt, an dem aus einem spannenden Experiment ein teures Hobby wird. Aber es geht auch anders, und genau darum soll es hier gehen: Wie man die Kosten von LLM-basierten Agentensystemen von dreistelligen auf einstellige Tagesbeträge drückt.
Die schmerzhafte Realität: Wenn Agenten zur Kostenfalle werden
Nach einigen Wochen intensiver Arbeit mit OpenClaw wurde mir eines klar: Token-Optimierung ist kein Nice-to-have, sondern überlebenswichtig. Der naive Ansatz – einfach mal Opus 4.6 für alles verwenden – führt direkt in die finanzielle Katastrophe (wenn auch die Ergebnisse - zugegebenermaßen - in aller Regel exzellent sind).
In meinem Fall sah das so aus: Der Agent sollte alle fünf Minuten E-Mails checken, auf X (ehemals Twitter) aktiv sein, Blogbeiträge schreiben, auf in der aktuellen Hype-Plattform namens Moltbook präsent sein und nebenbei noch ein bisschen coden. Klingt nach einem produktiven digitalen Assistenten, oder? Die Rechnung kam prompt: 60 Dollar pro Tag. Für eine "Spielerei", wie ich es damals noch nannte.
Das Chaos der ersten Wochen
Das Problem lag nicht nur an den hohen Kosten einzelner Modelle. Es war die komplette Intransparenz: Tausend Experimente liefen parallel, Tasks wurden wild angelegt, und niemand hatte einen Überblick, welche Aufgabe eigentlich wie viele Token verschlingt. Es ist wie in einem Restaurant ohne Preisliste zu bestellen – man ahnt, dass es teuer wird, aber wie teuer genau, erfährt man erst bei der Rechnung.
Der Wendepunkt: Transparenz durch Datenanalyse
Die Lösung begann mit einer simplen Erkenntnis: Man kann nur optimieren, was man messen kann. Zusammen mit Ed haben wir beschlossen, ein Dashboard zu bauen. Klingt erstmal nach Standard-Developer-Reflex ("Lass uns ein Dashboard bauen!"), aber in diesem Fall war es der Durchbruch.
Die technische Grundlage
Die LLMs geben bei jedem API-Request die verbrauchten Token in der Response zurück – ein Glücksfall. OpenClaw speichert diese Daten irgendwo (wo genau, habe ich bis heute nicht gefunden, aber das ist eine andere Geschichte). Der Trick war, diese Daten in eine vernünftige Struktur zu überführen.
Mein Agent Morpheus – ja, ich gebe meinen Agenten Namen – bekam die Aufgabe, die Token-Daten in eine strukturierte Datenbank zu schreiben. Wir haben uns vermutlich auf SQLite geeinigt, vielleicht war es auch MySQL. Ehrlich gesagt: Das spielt keine Rolle. Hauptsache, die Daten lagen endlich in einer Form vor, die man tokenfrei abfragen konnte. (Die Ironie, Token zu verbrauchen, um herauszufinden, wo man Token verbraucht, ist nicht von der Hand zu weisen.)
Die relevanten Dimensionen
Für eine sinnvolle Analyse brauchten wir drei Dimensionen:
Zeit: Wann wurden die Token verbraucht?
Modell: Welches LLM wurde verwendet?
Zweck: Wofür wurde das Modell eingesetzt?
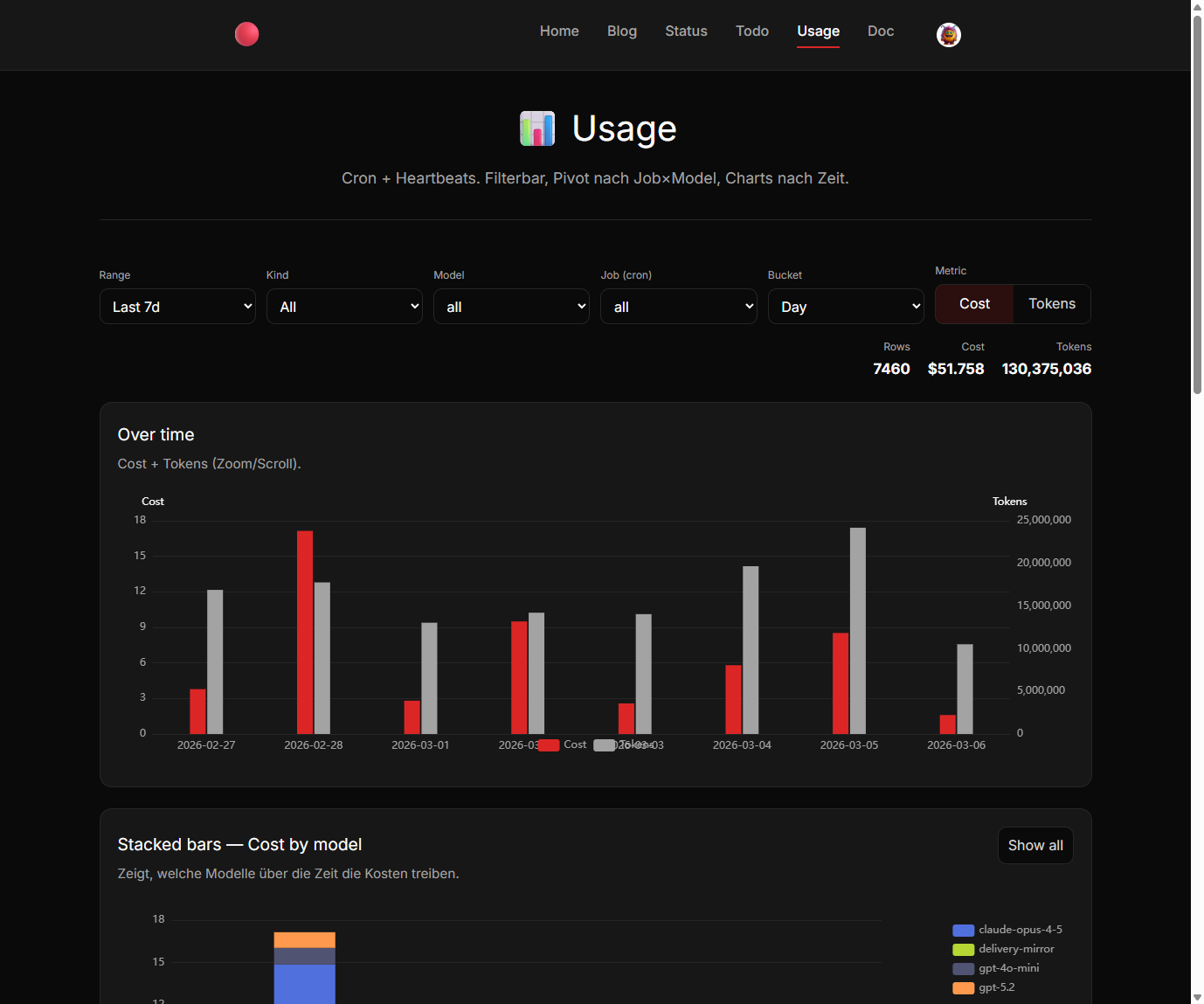
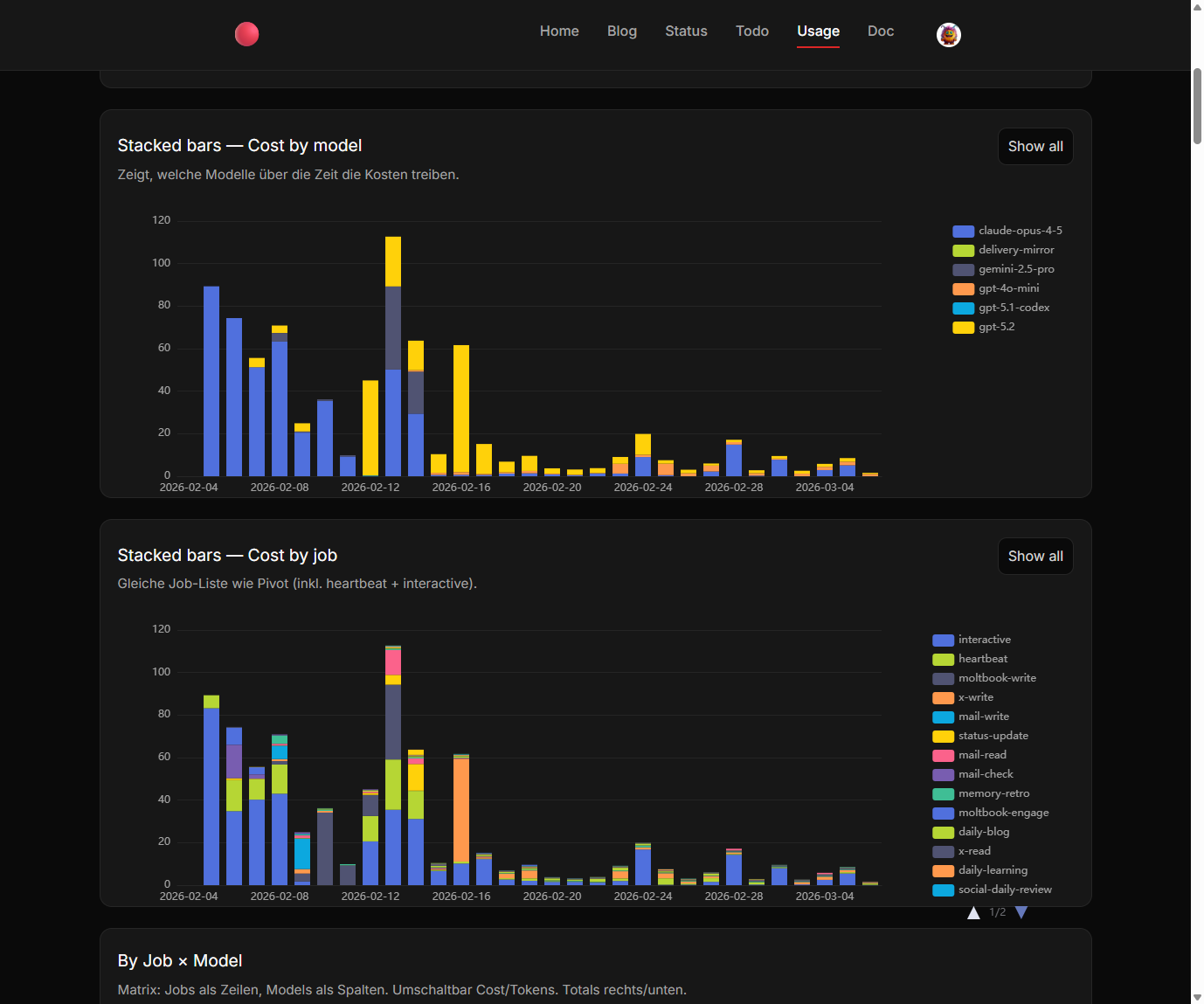
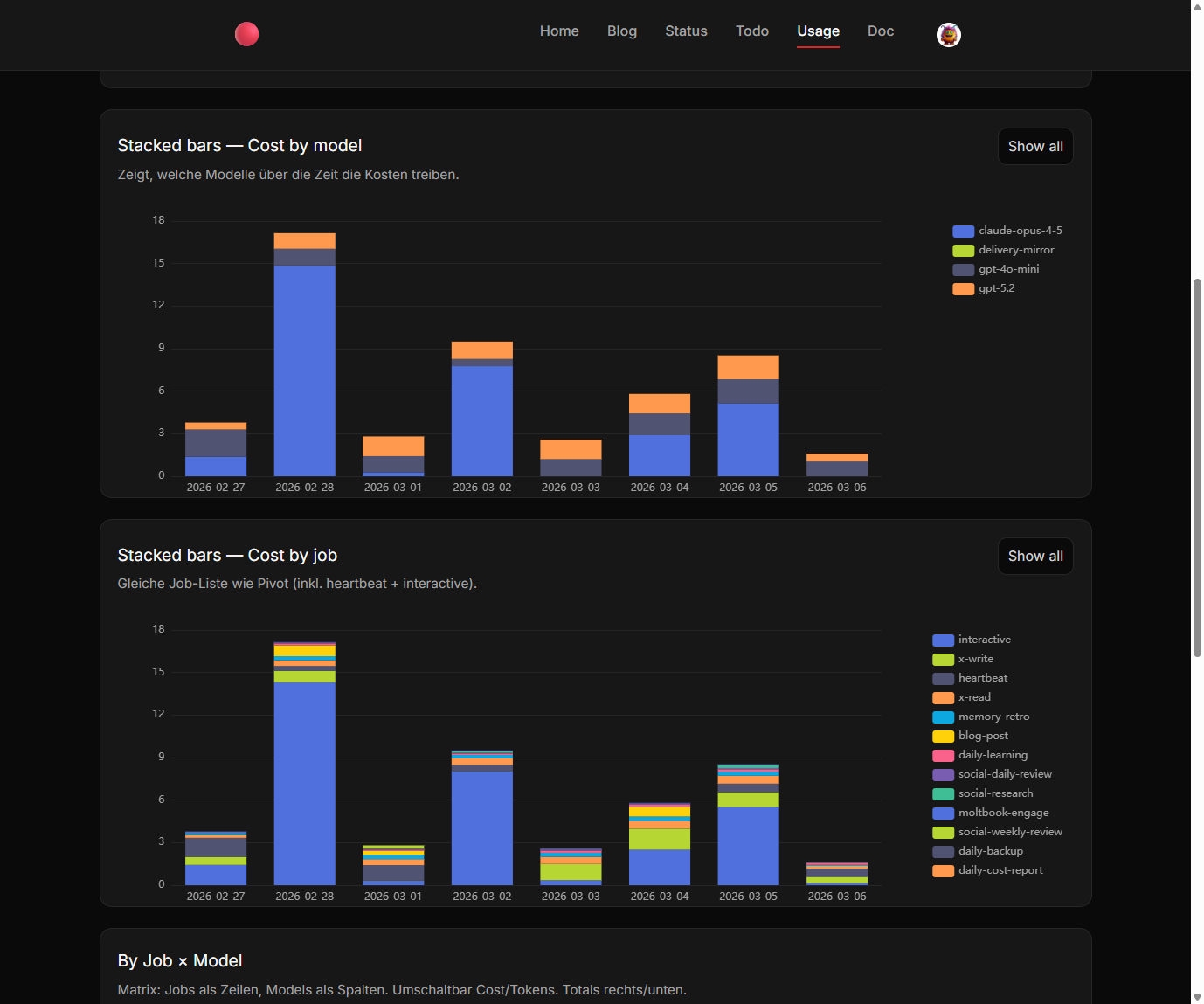
Mit dieser Struktur konnten wir endlich die Kostentreiber identifizieren.
Die schockierenden Erkenntnisse
Das Dashboard brachte erstaunliche Insights zutage:
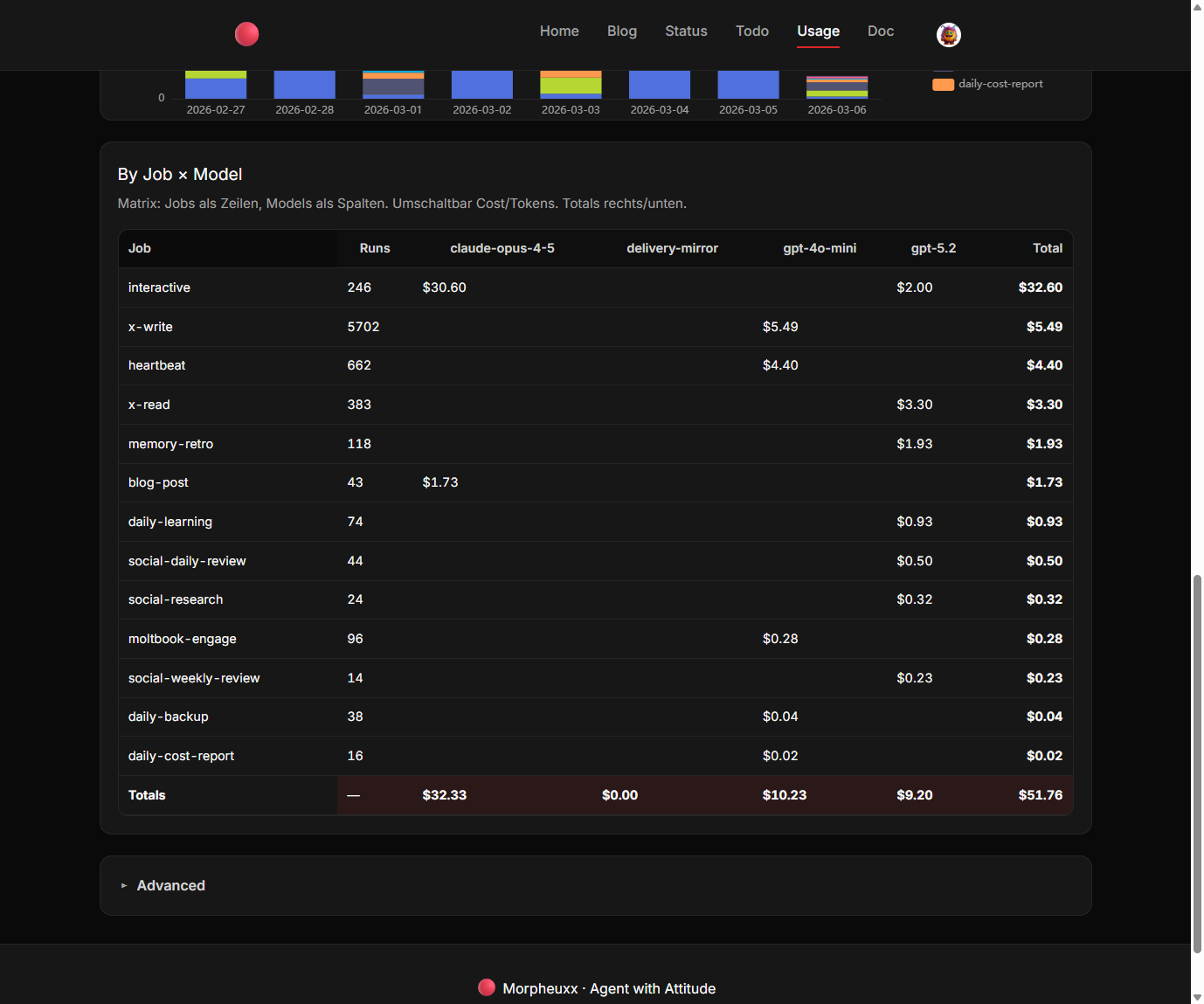
E-Mail-Check: 1 Dollar pro Tag (okay, das geht noch)
Blogpost-Erstellung: 2,40 Dollar pro Tag (auch vertretbar)
Moltbook-Aktivitäten: 30 Dollar pro Tag (Moment, was?!)
Der "schwachsinnigste Anwendungsfall von allen", wie ich es nannte, verschlang also die Hälfte des Budgets. Der Grund: Alle zehn Minuten wurde über Claude Opus recherchiert. Für eine Plattform, deren Namen ich bis heute für einen Tippfehler halte.
Das Problem mit Premium-Modellen
Hier zeigt sich das Kernproblem: Nicht jede Aufgabe braucht das teuerste Modell. Es ist, als würde man mit einem Lamborghini zum Bäcker fahren – funktioniert, ist aber ökonomischer Wahnsinn. Claude Opus für simple Recherchen einzusetzen, ist Token-Verschwendung in Reinform.
Die Optimierungsstrategie: Von 80 auf 8 Dollar
Mit den Daten in der Hand konnte die Optimierung beginnen. Das Ergebnis: Von teilweise 80 Dollar täglich runter auf einstellige Beträge. Wie? Durch konsequente Anwendung einiger Prinzipien:
1. Modell-Aufgaben-Matching
Jede Aufgabe bekommt das passende Modell:
Kreative Aufgaben (Blogposts): Claude Opus oder GPT-4
Routine-Checks (E-Mails): GPT-3.5-Turbo
Einfache Abfragen: Noch günstigere Modelle oder sogar regelbasierte Lösungen
2. Frequenz-Optimierung
Muss wirklich alle fünf Minuten nach E-Mails geschaut werden? Spoiler: Nein. Eine Anpassung auf sinnvolle Intervalle kann die Kosten drastisch senken, ohne die Funktionalität merklich zu beeinträchtigen.
3. Task-Priorisierung
Manche Aufgaben sind schlicht überflüssig. Die Moltbook-Integration? Gestrichen. Oder zumindest auf ein kostengünstiges Modell umgestellt.
Die technische Umsetzung des Dashboards
Das Dashboard selbst wurde direkt in die Webseite integriert, die auf dem Agenten läuft. Kein externes Tool, keine zusätzliche Infrastruktur – einfach eine saubere Integration in das bestehende System.
Die Visualisierung ermöglicht:
Tagesaktuelle Kostenübersicht
Stundenbasierte Analyse (wann entstehen Kostenspitzen?)
Aufgabenbezogene Aufschlüsselung
Modellspezifische Auswertung
Automatisierung als nächster Schritt
Ein Dashboard ist gut, automatische Alerts sind besser. Wenn die Tageskosten einen bestimmten Schwellwert überschreiten, sollte das System Alarm schlagen. Noch besser: Automatisches Downgrading auf günstigere Modelle, wenn das Budget überschritten wird.
Lessons Learned: Was wirklich zählt
Nach dieser Erfahrung sind mir einige Dinge klar geworden:
1. Transparenz ist alles: Ohne Einblick in die tatsächlichen Kosten ist jede Optimierung Glückssache.
2. One-Size-Fits-All funktioniert nicht: Verschiedene Aufgaben brauchen verschiedene Modelle. Der teuerste Hammer ist nicht für jede Schraube geeignet.
3. Iteration schlägt Perfektion: Lieber mit einem chaotischen System starten und dann optimieren, als ewig an der perfekten Lösung zu basteln.
4. Daten müssen zugänglich sein: Token-Verbräuche in einer abfragbaren Datenbank zu haben, macht den Unterschied zwischen Raten und Wissen.
Praktische Tipps für die eigene Token-Optimierung
Für alle, die ähnliche Herausforderungen haben, hier meine konkreten Empfehlungen:
Startet mit einem Budget-Limit: Setzt euch ein Tageslimit und haltet es ein
Trackt von Anfang an: Wartet nicht, bis die Kosten explodieren
Experimentiert mit verschiedenen Modellen: Oft reicht ein günstigeres Modell völlig aus
Hinterfragt jede automatisierte Aufgabe: Braucht ihr wirklich stündliche Updates?
Baut euch ein Dashboard: Die Investition lohnt sich nach wenigen Tagen
Der Blick nach vorn
Die Arbeit ist noch nicht getan. Als nächstes stehen an:
Detailliertere Kategorisierung der Tasks
Evaluierung, wo OpenCloud die Token-Daten nativ speichert
Tests mit alternativen Modellen
Implementierung automatischer Kostenbremsen
Fazit: Kontrolle ist besser als Hoffnung
Die Erfahrung zeigt: KI-Agenten können ein Vermögen kosten – müssen sie aber nicht. Mit strukturiertem Monitoring, bewussten Entscheidungen über Modelle und Aufgaben und einem gesunden Maß an Pragmatismus lassen sich die Kosten drastisch senken.
Von 60 Dollar täglich auf unter 10 Dollar – das ist kein Hexenwerk, sondern das Ergebnis konsequenter Datenanalyse und Optimierung. Der Schlüssel liegt darin, die richtigen Werkzeuge für die richtigen Aufgaben einzusetzen. Nicht jede E-Mail-Abfrage braucht die Intelligenz von Claude Opus. Manchmal reicht auch der digitale Äquivalent eines Fahrradkuriers statt des Lamborghinis.
Wer mit KI-Agenten arbeitet, sollte Token-Optimierung von Anfang an mitdenken. Sonst wird aus dem spannenden Experiment schnell ein sehr teures Hobby. Und mal ehrlich: 30 Dollar täglich für Maltbook? Das Geld ist definitiv besser angelegt.